Field(进阶版)
现代处理器内核的运算速度往往比配套的内存系统高出几个数量级。 为了缩小这一性能差距,计算机架构中采用了多级缓存系统和高带宽多通道内存。
在你熟悉了 Taichi Field 的基础知识之后,本文将帮助你进一步了解对编写高性能 Taichi 程序至关重要的底层内存布局。 我们还将特别介绍如何有效地组织数据布局以及如何管理内存占用。
组织高效的数据布局
本节将介绍如何组织 Taichi field 的数据布局。 高效数据布局的核心原则是局部性。 一般来说,一个具有理想局部性的方案至少具有以下特点之一:
- 稠密数据结构
- 小范围数据循环(对大多数处理器而言 32 KB 内)
- 顺序加载与存储数据
note
请注意,数据总是从内存中以块(页)为单位获取的。 此外,硬件本身并不了解块内某一具体的数据元素是如何使用的。 处理器只管从请求的内存地址读取整个块的数据。 因此,当数据没有得到充分利用时,内存带宽将被浪费。
如需了解稀疏 field,请参阅 稀疏计算。
布局 101:从 shape 到 ti.root.X
在基本用法中,我们使用 shape 描述符来构建一个 field。 Taichi 提供了灵活的语句 ti.root.X,用于描述更复杂的数据组织。 以下是一些例子:
- 声明一个零维 filed:
x = ti.field(ti.f32)
ti.root.place(x)
# is equivalent to:
x = ti.field(ti.f32, shape=())
- 声明一个形状为
3的一维 field:
x = ti.field(ti.f32)
ti.root.dense(ti.i, 3).place(x)
# is equivalent to:
x = ti.field(ti.f32, shape=3)
- 声明一个形状为
(3, 4)的二维 field:
x = ti.field(ti.f32)
ti.root.dense(ti.ij, (3, 4)).place(x)
# is equivalent to:
x = ti.field(ti.f32, shape=(3, 4))
你也可以把两个一维 dense 语句嵌套起来,以描述有着相同形状的二维数组。
x = ti.field(ti.f32)
ti.root.dense(ti.i, 3).dense(ti.j, 4).place(x)
# has the same shape with
x = ti.field(ti.f32, shape=(3,4))
note
上述用嵌套 dense 语句构建的二维数组和用 ti.field 构建的二维数组不完全相同。 虽然这两种语句都会产生相同形状的二维数组,但它们的 SNodeTree 层级不一样,如下所示:
以下代码片段在根节点下方有两个 SNodeTree:
x = ti.field(ti.f32)
ti.root.dense(ti.i, 3).dense(ti.j, 4).place(x)
以下代码片段在根节点下方只有一个 SNodeTree:
x = ti.field(ti.f32)
ti.root.dense(ti.ij, (3, 4)).place(x)
# or equivalently
x = ti.field(ti.f32, shape=(3,4))
下方的示意图说明这些层之间的差异:
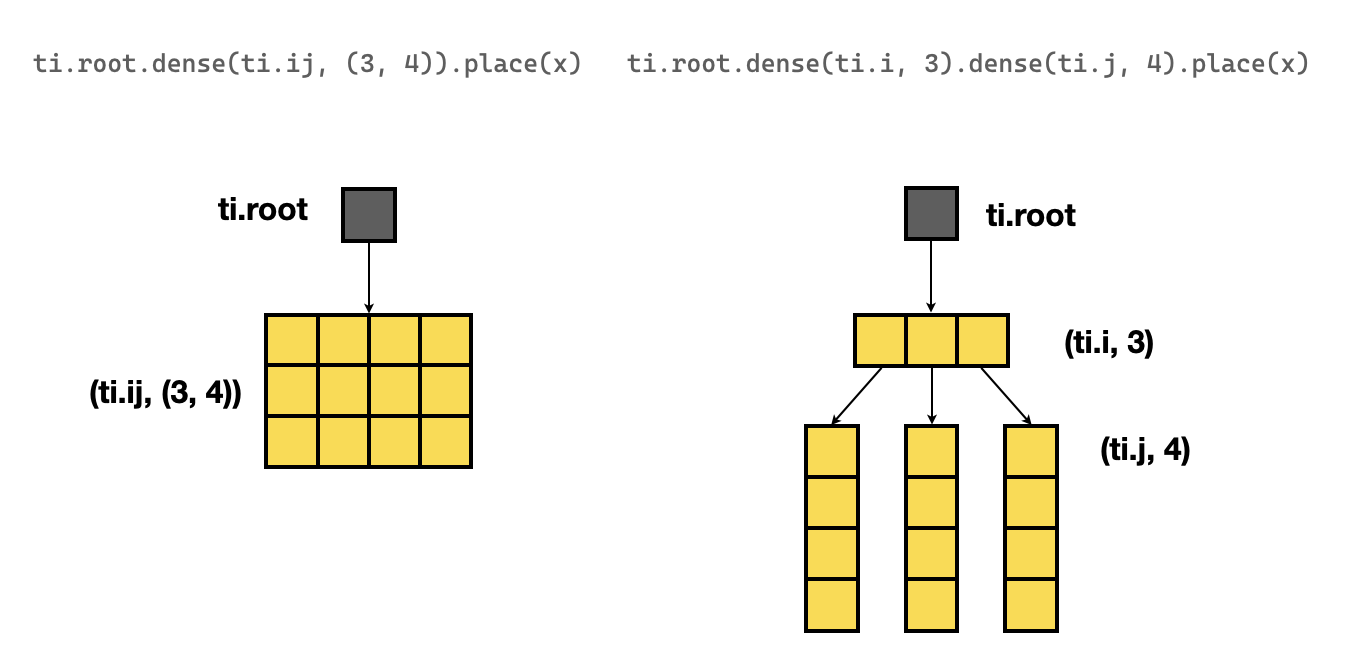
这里的差别是微妙的,因为两个数组都是行主序, 但可能会对性能产生轻微影响,因为计算 SNodeTree 索引的开销不同。
简而言之, ti.root.X 语句逐步将 field 的形状绑定到对应的轴。 通过多个语句的嵌套,我们可以构建一个更高维度的 field。
你可以使用 for 循环来遍历嵌套语句:
for i, j in A:
A[i, j] += 1
Taichi 编译器能够自动推断底层的数据布局并应用合适的数据读取顺序。 这是 Taichi 编程语言相较其他大多数通用编程语言的一大优势。在这些语言中,数据读取顺序只能手动优化。
行主序 vs. 列主序
关于内存地址的一个重要问题是它们的空间是线性的。 在不失一般性的情况下,我们忽略数据类型的差异,并假定每个数据元素形状都为 1。 此外,我们把一个 field 的起始内存地址标为 base,那么一维 Taichi field 的第 i 个元素的索引公式是 base + i。
对于多维 field,我们可以通过以下两种方式将高维索引平展到线性内存地址空间: 以一个形状为 (M, N) 的二维 field 为例,我们可以用长度为 N 的一维缓冲器存储 M 行,即行主序,或存储 N 列,即列主序。 对行主序第 (i, j) 个元素的索引平展公式为 base + i * N + j,对列主序则为 base + j * M + i。
同一行中的元素在行主序的 field 中是紧密排列的。 选择最佳布局的依据是如何访问元素,即访问模式。 如果在列主序的 field 中经常访问同一行元素,通常会导致性能退化。
Taichi field 的默认布局是行主序的。 你可以通过 ti.root 语句这样定义 field:
x = ti.field(ti.f32)
y = ti.field(ti.f32)
ti.root.dense(ti.i, M).dense(ti.j, N).place(x) # row-major
ti.root.dense(ti.j, N).dense(ti.i, M).place(y) # column-major
在上面的代码中,最右 dense 语句中的轴指称表示连续轴。 x field 中,同一行的元素(i 相同,j 不同)在内存中紧密排列,因此它是行主序;y field 中,同一列的元素(j 相同,i 不同)紧密排列,因此它是列主序。 我们通过 (2, 3) 这个例子可视化了 x 和 y 的内存布局:
# address: low ........................................... high
# x: x[0, 0] x[0, 1] x[1, 0] x[1, 1] x[2, 0] x[2, 1]
# y: y[0, 0] y[1, 0] y[2, 0] y[0, 1] y[1, 1] y[2, 1]
值得注意的是,Taichi field 的访问器是统一的:用相同的二维索引 x[i, j] 和 y[i, j] 访问第 (i, j) 个元素。 Taichi 在内部处理布局变量并应用合适的索引方程式。 由于这个功能,用户可以在定义中指定他们想要的布局,在使用 field 时不用担心底层的内存组织方式。 要改变布局, 我们可以简单地交换 dense 语句的顺序,并保留代码的其余部分。
note
以下代码片段为熟悉 C/C++ 的读者演示了 C 语言中 2D 数组的数据访问:
int x[3][2]; // row-major
int y[2][3]; // column-major
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 2; j++) {
do_something(x[i][j]);
do_something(y[j][i]);
}
}
x 和 y 的访问器在行主序数组和列主序数组之间分别为倒序。 与 Taichi field 相比,当你更改内存布局时,需要修改更多代码。
AoS vs. SoA
AoS 全称 array of structures(数组结构体),SoA 全称 structure of arrays(结构体数组)。 一个带有四个像素和三个颜色通道的 RGB 图像:AoS 布局存储 RGBRGBRGBRGB,而 SoA 布局存储 RRRRGGGGBBBB。 选择 AoS 还是 SoA 布局很大程度上取决于 field 的访问模式。 让我们讨论一个处理大规格 RGB 图像的场景。 这两个布局的内存安排如下:
# address: low ...................... high
# AoS: RGBRGBRGBRGBRGBRGB.............
# SoA: RRRRR...RGGGGGGG...GBBBBBBB...B
要计算每个像素的灰度,你需要所有颜色通道但不需要其他像素的值。 在这种情况下,AoS 布局提供更好的内存访问模式:因为颜色通道是连续存储的,相邻通道可以即时获取。 SoA 布局不是一个好选择,因为一个像素的颜色通道在内存空间中存储位置相隔很远。
我们将介绍如何使用 ti.root.X 语句构建 AoS 和 SoA field。 SoA field 很简单:
x = ti.field(ti.f32)
y = ti.field(ti.f32)
ti.root.dense(ti.i, M).place(x)
ti.root.dense(ti.i, M).place(y)
其中 M 是 x 和 y 的长度。 x 和 y 中的数据元素在内存中是连续的:
# address: low ................................. high
# x[0] x[1] x[2] ... y[0] y[1] y[2] ...
我们这样构建 AoS field:
x = ti.field(ti.f32)
y = ti.field(ti.f32)
ti.root.dense(ti.i, M).place(x, y)
内存布局就变成了
# address: low .............................. high
# x[0] y[0] x[1] y[1] x[2] y[2] ...
在这里, place 将 Taichi field x 和 y 中的元素交错排列。
正如先前所介绍的那样,无论是 AoS 还是 SoA,x 和 y 的访问方法都是一样的。 因此,可以在不修改申请逻辑的情况下灵活改变数据布局。
为了更好地说明,让我们看一个一维波方程求解器的示例:
N = 200000
pos = ti.field(ti.f32)
vel = ti.field(ti.f32)
# SoA placement
ti.root.dense(ti.i, N).place(pos)
ti.root.dense(ti.i, N).place(vel)
@ti.kernel
def step():
pos[i] += vel[i] * dt
vel[i] += -k * pos[i] * dt
上面的代码片段定义了 SoA field 和一个可以顺序访问每个元素的 step kernel。 这个 kernel 分别从 pos 和 vel 获取每次迭代的元素。 对于 SoA field,内存中任何两个元素最近的距离是 N,当 N 很大,这种方式不太可能高效。
如下面的代码所示,我们把布局切换为 AoS:
N = 200000
pos = ti.field(ti.f32)
vel = ti.field(ti.f32)
# AoS placement
ti.root.dense(ti.i, N).place(pos, vel)
@ti.kernel
def step():
pos[i] += vel[i] * dt
vel[i] += -k * pos[i] * dt
仅仅修改 place 语句就足以改变布局。 通过这个优化,即时元素 pos[i] 和 vel[i] 现在在内存中相邻,这样效率更高。<!-- ```python
SoA version
N = 200000 pos = ti.field(ti.f32) vel = ti.field(ti.f32) ti.root.dense(ti.i, N).place(pos) ti.root.dense(ti.i, N).place(vel)
@ti.kernel def step(): pos[i] += vel[i] dt vel[i] += -k pos[i] * dt
```python
# AoS version
N = 200000
pos = ti.field(ti.f32)
vel = ti.field(ti.f32)
ti.root.dense(ti.i, N).place(pos)
ti.root.dense(ti.i, N).place(vel)
@ti.kernel
def step():
pos[i] += vel[i] * dt
vel[i] += -k * pos[i] * dt
Here, pos and vel for SoA are placed separately, so the distance in address
space between pos[i] and vel[i] is 200000. This results in poor spatial
locality and poor performance. A better way is to place them together:
ti.root.dense(ti.i, N).place(pos, vel)
Then vel[i] is placed right next to pos[i], which can increase spatial
locality and therefore improve performance. --><!-- For example, the following places two 1D fields of shape 3 together, which
is called Array of Structures (AoS):
ti.root.dense(ti.i, 3).place(x, y)
Their memory layout is:
By contrast, the following places these two fields separately, which is called Structure of Arrays (SoA): --><!-- ```python ti.root.dense(ti.i, 3).place(x) ti.root.dense(ti.i, 3).place(y)
Now their memory layout is:
**To improve spatial locality of memory accesses, it may be helpful to
place data elements that are often accessed together within
relatively close addresses.** -->
### AoS 扩展:层级结构的 field
<!-- haidong: I hope to remove this subsection. This content just repeats the AoS topic --> 有时我们想要以某种复杂但固定的模式访问内存,比如在 8x8 的块中遍历图像。 表面上最佳做法是平展每个 8x8 的块并将它们连接在一起。 然而,此时 field 已不再是一个扁平缓存器,因为它有两个层级:图像层和块层。 也就是说,这个 field 是一个隐式 8x8 块结构的数组。
我们用如下语句表示:
```python
# Flat field
val = ti.field(ti.f32)
ti.root.dense(ti.ij, (M, N)).place(val)
# Hierarchical field
val = ti.field(ti.f32)
ti.root.dense(ti.ij, (M // 8, N // 8)).dense(ti.ij, (8, 8)).place(val)
其中 M and N 是 8 的倍数。 我们鼓励此种尝试。 你会发现性能差异巨大。
note
我们强烈建议你使用二次幂形式的块形状,以便能够通过位运算加速索引,更好地实现内存地址对齐。
管理内存占用
Field 的手动分配和销毁
一般情况下,Taichi 对内存的分配和销毁对用户是不可见的。 不过,用户有时会需要接管他们的内存分配。
针对这种情况,Taichi 提供了 FieldsBuilder,用于支持 field 相关内存的手动分配和销毁。 FieldsBuilder 和 ti.root 有相同的声明 API。 但还需要在所有声明之后调用 finalize()。 finalize() 返回一个 SNodeTree 对象用于处理随后的内存销毁。
我们来看一个简单的例子:
import taichi as ti
ti.init()
@ti.kernel
def func(v: ti.template()):
for I in ti.grouped(v):
v[I] += 1
fb1 = ti.FieldsBuilder()
x = ti.field(dtype=ti.f32)
fb1.dense(ti.ij, (5, 5)).place(x)
fb1_snode_tree = fb1.finalize() # Finalizes the FieldsBuilder and returns a SNodeTree
func(x)
fb1_snode_tree.destroy() # Destruction
fb2 = ti.FieldsBuilder()
y = ti.field(dtype=ti.f32)
fb2.dense(ti.i, 5).place(y)
fb2_snode_tree = fb2.finalize() # Finalizes the FieldsBuilder and returns a SNodeTree
func(y)
fb2_snode_tree.destroy() # Destruction
尽管 ti.root 具有自动管理内存分配和回收的能力,上面演示的 ti.root 语句是用由 FieldsBuilder 实现的。