用 Taichi 加速 PyTorch
Taichi 和 Torch 的应用场景不同,但可以相互补充。
- Taichi 对并行的控制更精细,且支持颗粒度更高的操作(元素层面),从而给予用户更大的灵活度。
- Torch 将此类细节抽象到 tensor 层面的操作中,好比乐高积木,使用户能够集中精力构建 ML(机器学习)模型。
本文档使用两个示例来解释如何使用 Taichi kernel 实现数据预处理算子和自定义高性能 ML 算子。
数据预处理
本节以边缘填充为例,演示 Taichi 如何助力 PyTorch 进行数据预处理。
边缘填充是机器学习中一种常用的数据预处理手段。 例如,边缘填充可以防止卷积操作改变输入图像的大小。 然而,没有特制的 PyTorch 算子支持在边缘上填充某个特定的图样。 此前,你有两个变通方法:
- 使用 Python 或 PyTorch 迭代矩阵元素。
- 编写 C++/CUDA 算子,并通过 Python 定制的算子扩展接入 PyTorch 。
前者的效率非常低下,可能拖慢神经网络训练的性能; 后者需要大量关于底层硬件架构的领域特定知识,可能需要很长时间才能上手。
现在,你可以使用 Taichi 更高效地用特定图样完成对一面砖墙的边缘填充。
下文比较了 PyTorch 的填充实现与 Taichi 的实现版本:
创建一个“砖块”并用渐变色填充。

在水平方向重复砖块,采用固定的偏移量形成交错的布局。

使用 PyTorch 进行边缘填充
以下代码为边缘填充实现了一个 PyTorch kernel torch_pad()。 为提高效率,这个 kernel 将边缘填充过程转变为一系列 PyTorch 的原生矩阵运算。 但这种矩阵运算往往并不直观,且需要将很多中间结果存储在 GPU 内存中,以致在 RAM 较小的老版 GPU 上甚至跑不起来。
def torch_pad(arr, tile, y):
# image_pixel_to_coord
arr[:, :, 0] = image_height - 1 + ph - arr[:, :, 0]
arr[:, :, 1] -= pw
arr1 = torch.flip(arr, (2, ))
# map_coord
v = torch.floor(arr1[:, :, 1] / tile_height).to(torch.int)
u = torch.floor((arr1[:, :, 0] - v * shift_y[0]) / tile_width).to(torch.int)
uu = torch.stack((u, u), axis=2)
vv = torch.stack((v, v), axis=2)
arr2 = arr1 - uu * shift_x - vv * shift_y
# coord_to_tile_pixel
arr2[:, :, 1] = tile_height - 1 - arr2[:, :, 1]
table = torch.flip(arr2, (2, ))
table = table.view(-1, 2).to(torch.float)
inds = table.mv(y)
gathered = torch.index_select(tile.view(-1), 0, inds.to(torch.long))
return gathered
with Timer():
gathered = torch_pad(coords, tile, y)
torch.cuda.synchronize(device=device)
使用 Taichi 进行边缘填充
以下代码实现了一个用于边缘填充的 Taichi kernel ti_pad()。 这个 kernel 遍历输出图像中的像素,计算出每个像素在输入“砖块”中的对应位置, 并用该位置的 RGB 颜色填充像素。
Taichi 自动并行运行顶层循环,且使用 Taichi 编写的矩阵运算可读性更强。 此外,正如以下代码所示,ti_pad() 直接接收 PyTorch 的 tensor,因而可以重用分配给 PyTorch 的内存,并且不会因两个框架间的数据传输造成额外的开销。
@ti.kernel
def ti_pad(image_pixels: ti.types.ndarray(), tile: ti.types.ndarray()):
for row, col in ti.ndrange(image_height, image_width):
# image_pixel_to_coord
x1, y1 = ti.math.ivec2(col - pw, image_height - 1 - row + ph)
# map_coord
v: ti.i32 = ti.floor(y1 / tile_height)
u: ti.i32 = ti.floor((x1 - v * shift_y[0]) / tile_width)
x2, y2 = ti.math.ivec2(x1 - u * shift_x[0] - v * shift_y[0],
y1 - u * shift_x[1] - v * shift_y[1])
# coord_to_tile_pixel
x, y = ti.math.ivec2(tile_height - 1 - y2, x2)
image_pixels[row, col] = tile[x, y]
with Timer():
ti_pad(image_pixels, tile)
ti.sync()
性能比较
如下表所示,PyTorch kernel 需要 30.392 毫秒1来完成边缘填充;Taichi kernel 只用了 0.267 毫秒。 Taichi 比 PyTorch 快 100 多倍(30.392/0.267)。
torch_pad() 启动了 58 个 CUDA kernel,而 Taichi 将所有计算都编译成一个 CUDA kernel。 CUDA kernel 越少,产生的 GPU 启动开销就越少。 此外,Taichi kernel 能够比 PyTorch kernel 节省更多冗余的内存操作。 GPU 启动开销和冗余的内存操作是程序优化和加速的潜在来源。
| Kernel 函数 | 平均用时(毫秒) | 启动的 CUDA kernel 数量 |
|---|---|---|
torch_pad() | 30.392 | 58 |
ti_pad() | 0.267 | 1 |
- GPU:RTX3090
- PyTorch 版本:v1.12.1;Taichi 版本:v1.1.0
- 实际加速比可能根据你的具体实现和 GPU 设置而变化。
定制 ML 算子
机器学习研究人员通常花费大量时间设计模型架构。 因为他们发现 PyTorch 无法为新设计或定制的算子提供良好支持, 他们不得不花时间学习 CUDA,以调优性能、提高效率。 但用 CUDA 编写算子很难,调优 CUDA 代码更难,用 CUDA 加速模型迭代难上加难。
此仓库 介绍了一个在 CUDA 中定制 ML 算子的例子。 仓库作者利用某种一维深度卷积的自定义算子开发了 RWKV 语言模型。 这一模型不涉及大量计算,但仍然运行缓慢,因为没有 PyTorch 的原生支持。 因此,作者利用多种优化技巧,包括循环合并和共享内存(Shared Memory),在 CUDA 中定制算子,达到 PyTorch 性能的 20 倍。
参考 CUDA 代码3,我们使用相同的优化手段,在 RWKV 模型中定制了一个 Taichi 深度卷积算子4。
深度卷积算子的功能:
- 遍历两个输入的 tensor,即
w和k, - 计算
w和k中对应位置元素的乘积s, - 将
s保存到输出的 tensorout中。
以下小节以基准实现方式为例,展示了如何分别用 Python、PyTorch、CUDA,和 Taichi 实现深度卷积算子,并进行了对比。 使用 Taichi,你可以轻松加速 ML 模型的开发,不再为低级并行编程烦恼。
| 实现方案 | 可读性 | 性能调优 |
|---|---|---|
| Python | 好 | 最慢 |
| PyTorch | 差 | 慢 |
| CUDA | 差 | 快 |
| Taichi | 好 | 媲美甚至超过 CUDA |
使用 Python 实现深度卷积算子
Python 参考代码简单易懂, 但速度太慢,结果甚至难以放进下文的比较图中。
def run_formula_very_slow(w, k, B, C, T, eps):
out = torch.empty((B, C, T), device='cpu')
for b in range(B):
for c in range(C):
for t in range(T):
s = eps
for u in range(t-T+1, t+1):
s += w[c][0][(T-1)-(t-u)] * k[b][c][u+T-1]
out[b][c][t] = s
return out
使用 PyTorch 实现深度卷积算子
将上面的 Python 参考代码翻译成如下的这一行代码并不容易。 要做到这一点,你必须非常清楚这些 PyTorch 算子的底层逻辑。
out = eps + F.conv1d(nn.ZeroPad2d((T-1, 0, 0, 0))(k), w.unsqueeze(1), groups=C)
使用 CUDA 实现深度卷积算子
CUDA 参考代码的可读性要低得多:最外层循环的定义隐含在线程并行中。 索引的计算很复杂,每个元素在矩阵中的位置并不一目了然。 而且使用 CUDA 实现更为复杂的算法很容易出错。
__global__ void kernel_forward(const float* w, const float* k, float* x,
const float eps, const int B, const int C, const int T)
{
const int i = blockIdx.y;
const int t = threadIdx.x;
float s = eps;
const float* www = w + (i % C) * T + (T - 1) - t;
const float* kk = k + i * T;
for (int u = 0; u <= t; u++){
s += www[u] * kk[u];
}
x[i * T + t] = s;
}
此外,你需要一个合适的编译环境来运行 CUDA 代码。 如果你已经将 CUDA 代码预编译入一个动态链接库, 你还需要花时间处理繁琐的事项,诸如环境设置和 Python API 封装。
使用 Taichi 实现深度卷积算子
Taichi 参考代码与 Python 版本几乎完全相同。 Taichi 相比于 CUDA 的一个优势在于,你可以轻松用 Taichi 实现相似的性能而无需担心并行和指针偏移等低级细节。
@ti.kernel
def taichi_forward_v0(
out: ti.types.ndarray(ndim=3),
w: ti.types.ndarray(ndim=3),
k: ti.types.ndarray(ndim=3),
eps: ti.f32):
for b, c, t in out:
s = eps
for u in range(t-T+1, t+1):
s += w[c, 0, (T-1)-(t-u)] * k[b, c, u+T-1]
out[b, c, t] = s
性能比较
由下表可见,Taichi 总是达到与 CUDA 相当的性能,甚至在某些情况下超过了 CUDA。
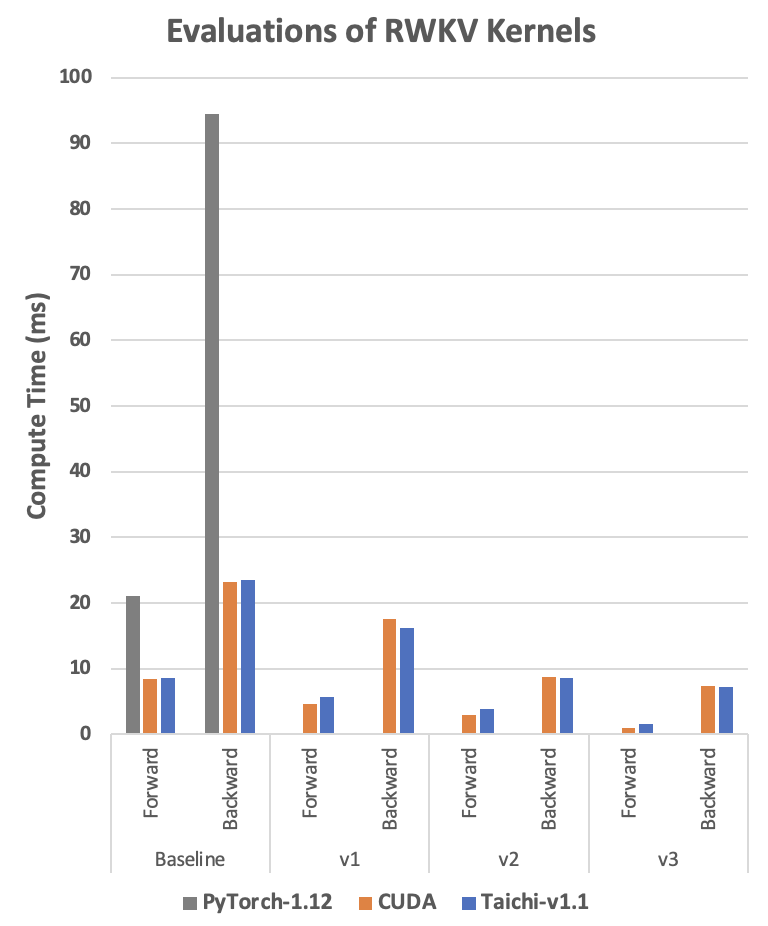
- 表中的 RWKV 运算时间以毫秒为单位。 运算时间越少,性能越好。
- 基准(Baseline):参考代码直接实现算法,不做任何改动。
- v1 ~ v3:三种不同的优化版本。
总结
PyTorch 能够有效地处理机器学习中的大部分计算任务。 但仍有需求尚未得到解决,比如对许多算子的原生支持和不尽如人意的运行时性能。
作为嵌入 Python 的高性能编程语言,Taichi 拥有以下特性:
- 易读性,
- 优化内存消耗,
- 媲美 CUDA 的运行时性能,
- 易移植性,可鼓励社区分享可复现的代码。
这些特性让 Taichi 作为 ML 算子定制的便利工具脱颖而出。本文档提供的两个例子解释了 Taichi 和 PyTorch 如何相互补充,共同解决现实的高性能编程问题。
参考内容
1 PyTorch 边缘填充 2 在 Taichi kernel 中实现 PyTorch 算子的边缘填充 3 RWKV-CUDA 4 RWKV-Taichi